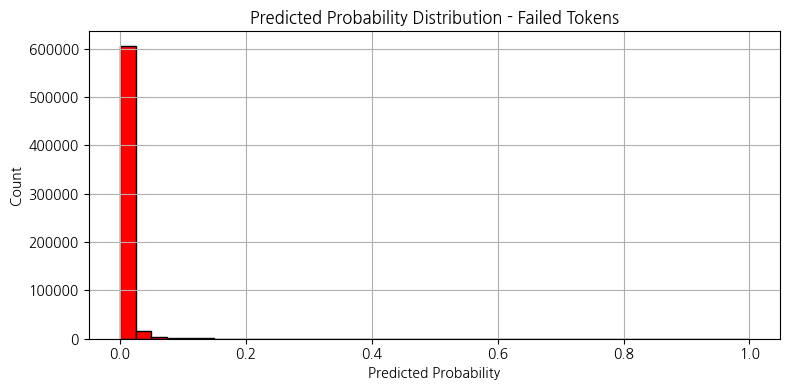
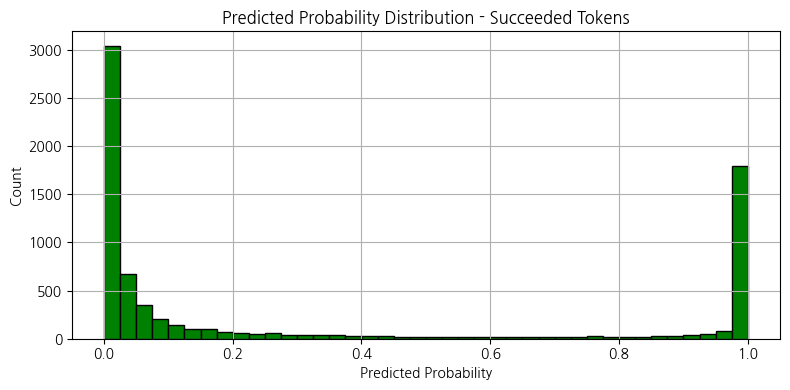
거래 후, 유동성 풀에 남아 있는 토큰의 가상 잔고 높을수록 → 사람들이 토큰을 덜 샀거나, 매도서 토큰이 다시 풀로 들어왔다는 뜻
virtual_sol_balance_after
거래 후, 유동성 풀에 남아 있는 SOL의 가상 잔고 높을수록 → 많은 사람들이 이 토큰을 샀다는 뜻
signature
트랜잭션 서명 트랜잭션의 고유 ID 같은 역할 (지갑 주소가 실제로 서명했는지 인증)
provided_gas_fee
사용자가 제시한 총 gas 비용 트랜잭션을 보낼 때 “이 정도까지는 수수료로 지불하겠다”는 상한선
provided_gas_limit
최대 사용 가능 gas 양 트랜잭션 실행에 허요된 최대 계산량 (계산 복잡도 제한치)
fee
실제로 지불된 수수료 트랜잭션 처리 후 실제로 빠져나간 SOL 수수료 (보통 provided_gas_fee보다 작음)
consumed_gas
실제로 사용된 gas 양 이 트랜잭션을 실행하는 데 소모된 계산량 (실제 연산량)
dune_token_info.csv
Dune Analytics에서 수집된 토큰 메타데이터
token_mint_address
토큰의 민트 주소 (고유 ID)
decimals
토큰이 소수점 이하로 몇 자리까지 표현 가능한지 같은 숫자라도 실제 양은 다를 수 있음 amount / (10^decimals) 로 정상화해서 다뤄야 함
name, symbol
토큰의 이름과 심볼(브랜딩 정보)
token_uri
IPFS에 저장된 메타데이터 링크
created_at
해당 토큰이 민트된 시각
init_tx
초기 민팅 트랜잭션 해시값 (트랜잭션 고유 ID) - 블록체인에서는 모든 거래가 고유한 해시 값을 가짐 - 이 컬럼은 그 중에서도 이 토큰을 생성한 최초의 거래를 가리킴 - solscan 같은 사이트에서 검색하면, 토큰 생성 시점에 무슨 일이 있었는지 볼 수 있음 - httsp://solscan.io/tx/[init_tx] 로 검색하면 생성 내역 조회 가능
token_info_onchain_divers.csv
토큰 메타데이터 + 배포 관련 통계
block_time, slot, tx_idx
해당 토큰이 민트된 시점의 시간/슬록/트랜잭션 인덱스
creator
이 토큰을 만든 지갑 주소(배포자)
mint
토큰 민트 주소
bundle_size
민트 트랜잭션 안에 한 번에 생성된 토큰 수
gas_used
토큰 생성시 사용된 가스량
name, symbol, url
토큰의 이름, 심볼, 메타데이터 URI
amount_of_instructions
curve_address
유동성 풀의 특정 커브(곡선) 로직을 정의한 스마트 컨트랙트 주소 - 유동성 풀이 어떤 가격 결정 로직을 따르는지를 지정한 스마트 컨트랙트 주소 - 곡선이 다르면 가격 반응성, 슬리피지, 수익 모델이 다름
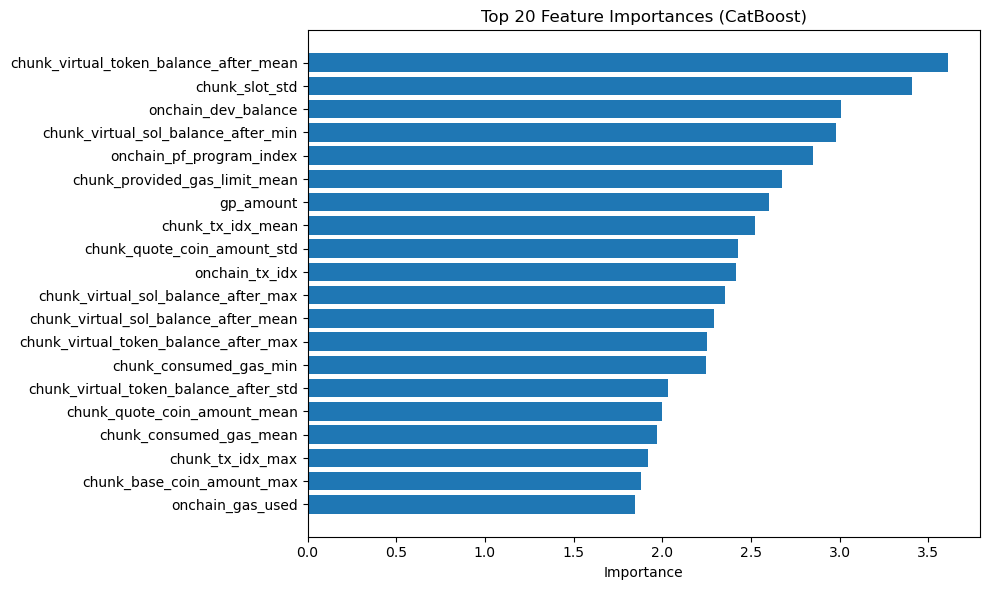
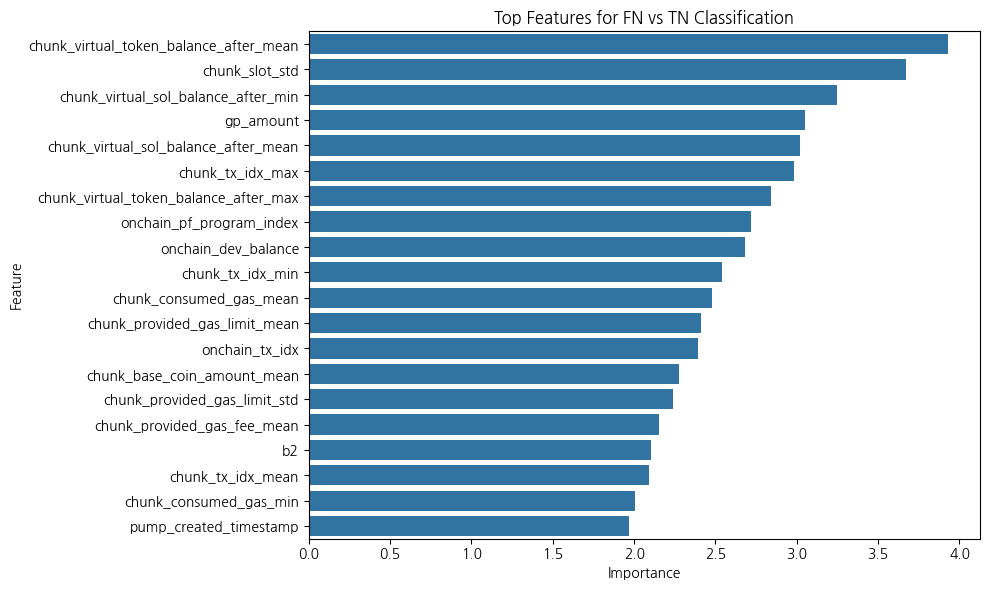
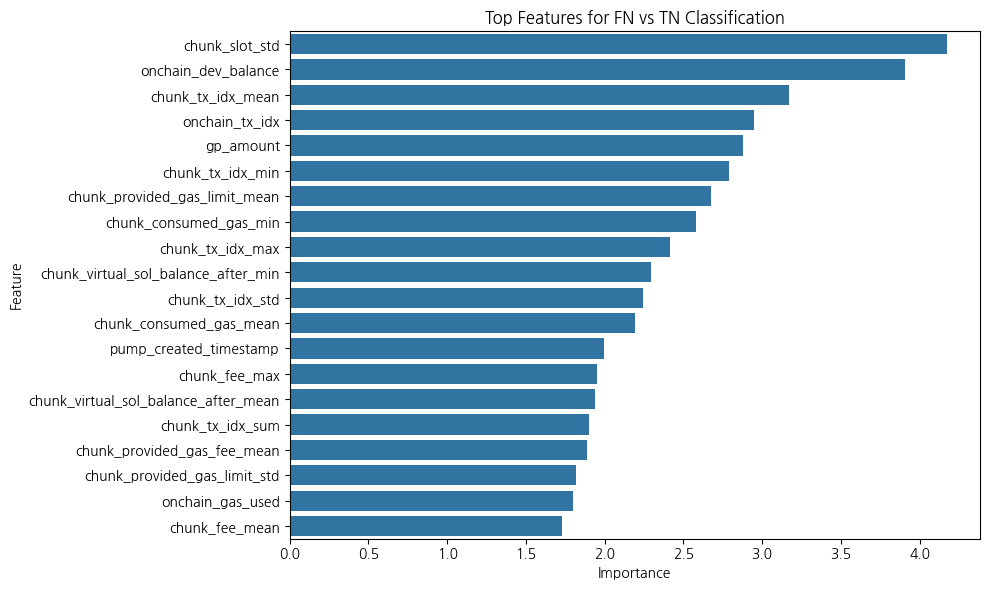
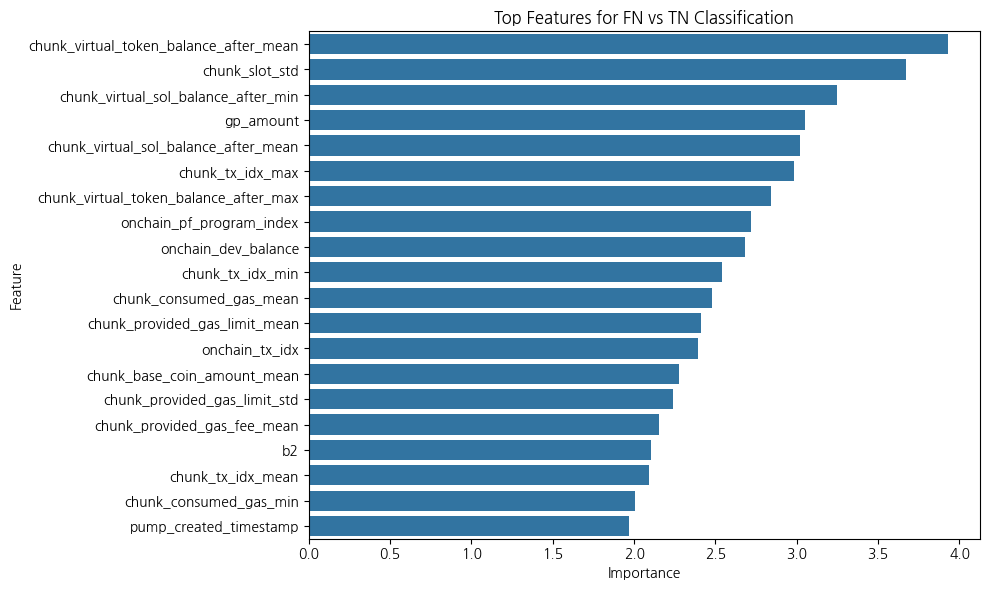
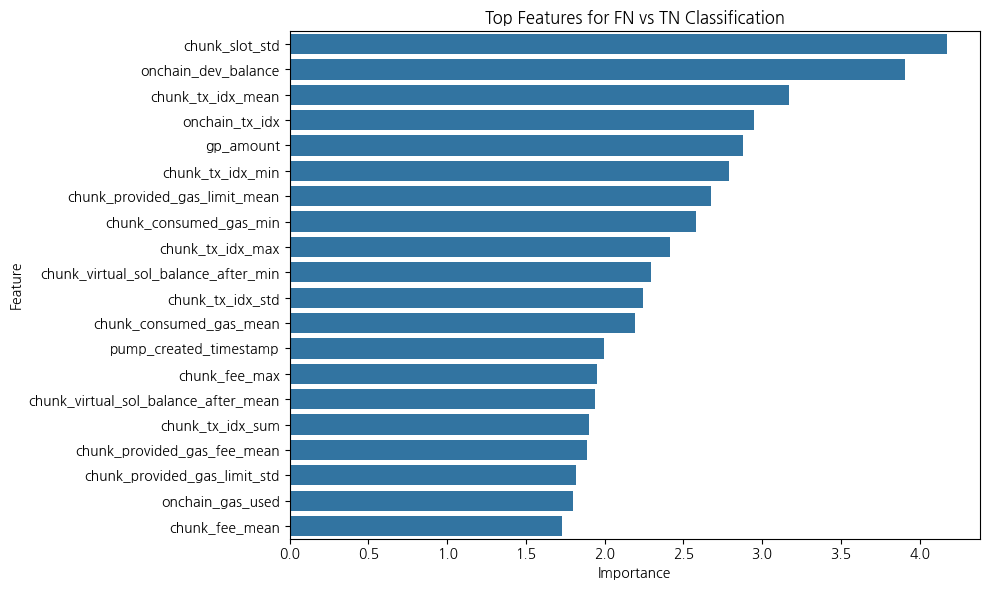
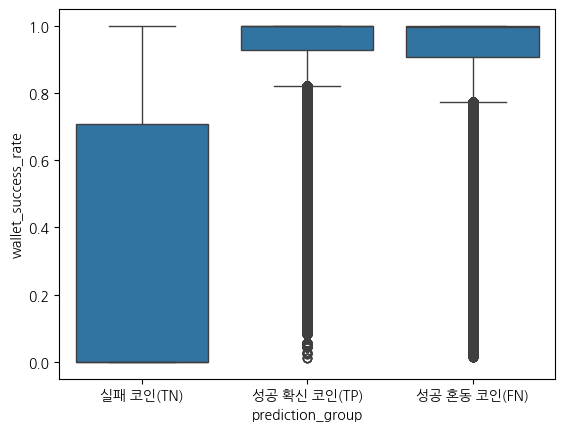
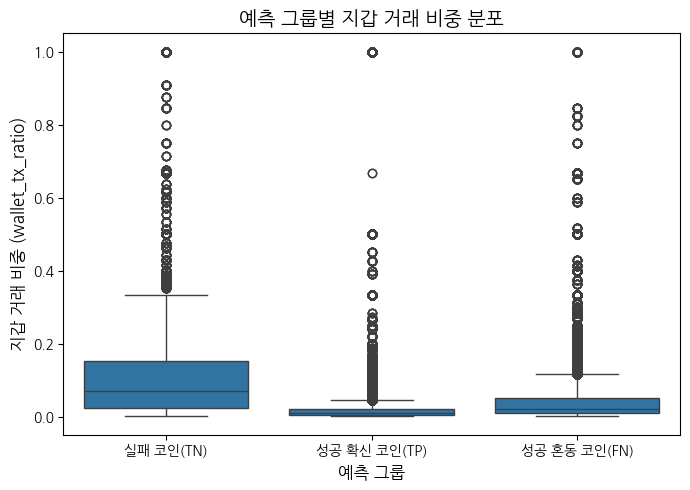
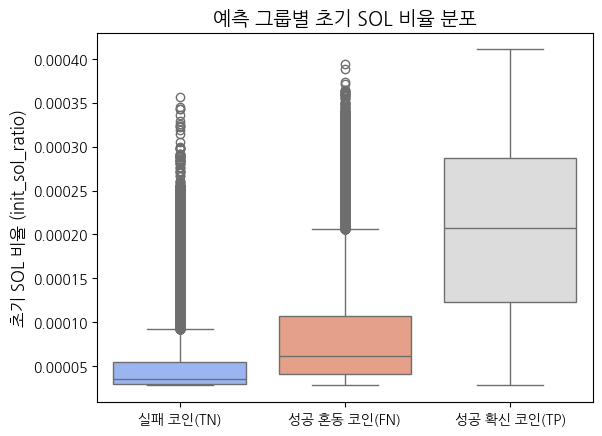
각 거래 내역에서 거래를 한 지갑(사람)이 투자한 코인의 성공률을 계산하여 wallet_success_rate 라는 feature를 만들고, 각 코인 별로 갖고 있는 wallet_success_rate 값을 mean, std, min, max, sum 으로 집계를 내려서 최종 feature 로 추가
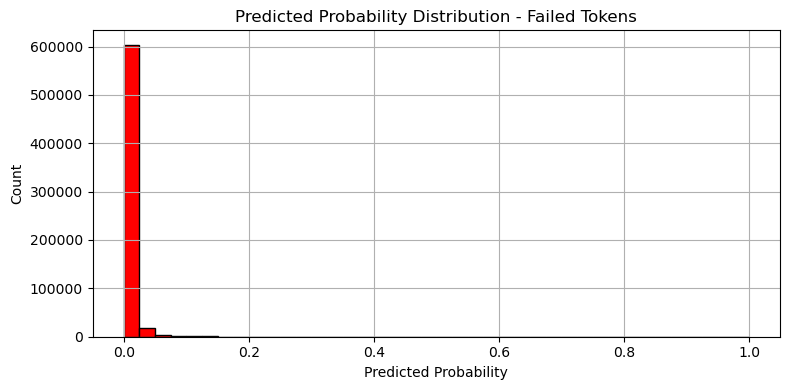
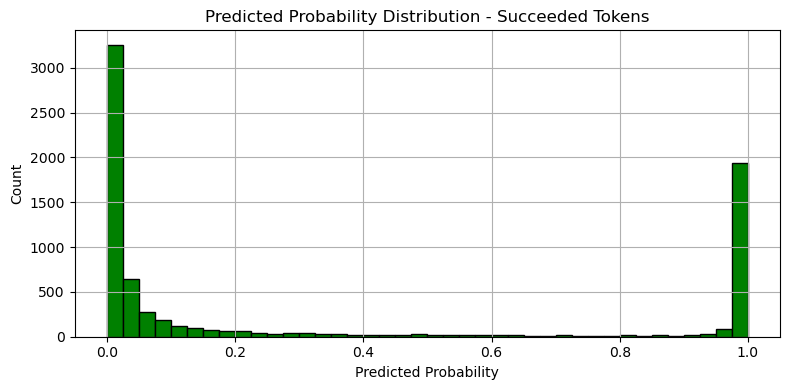
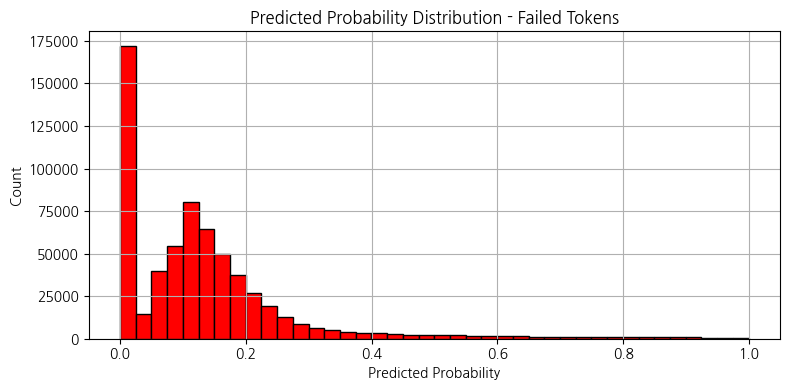
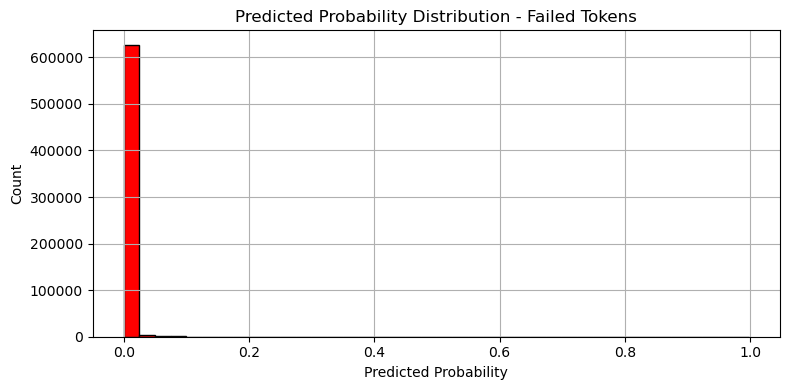
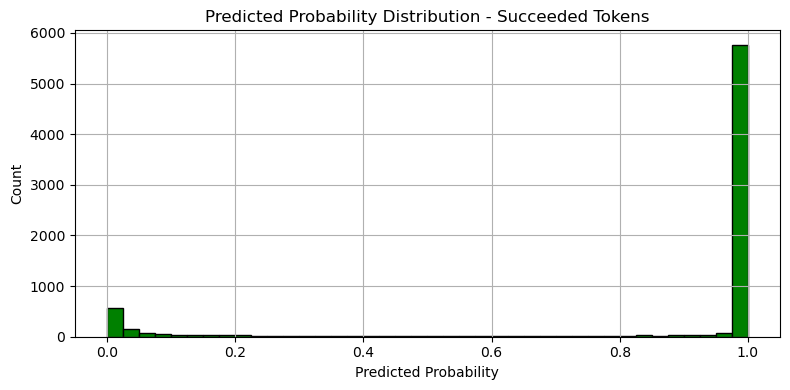
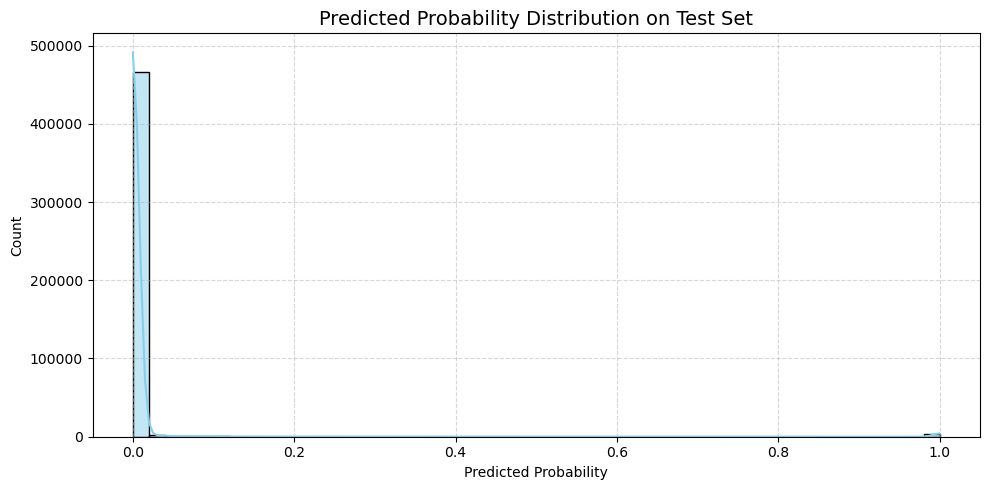
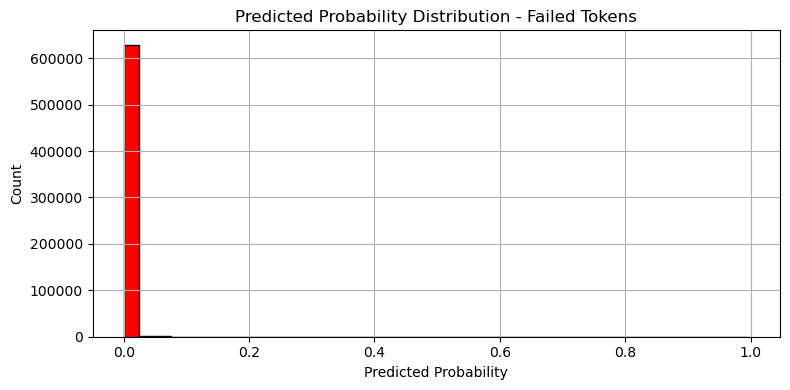
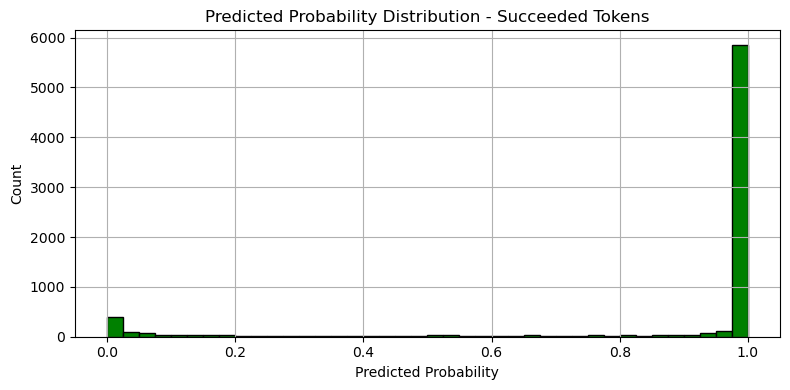
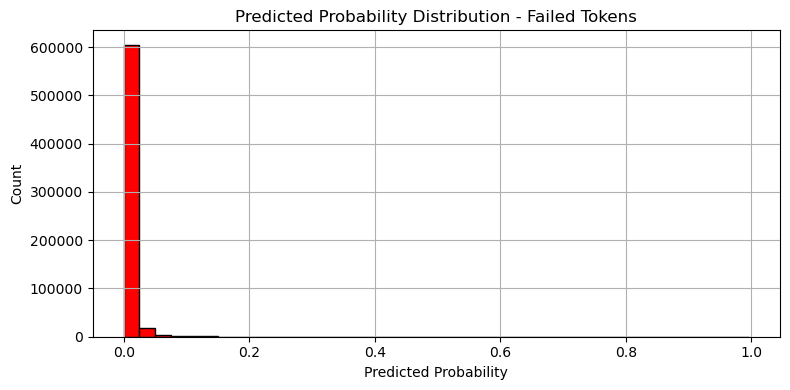
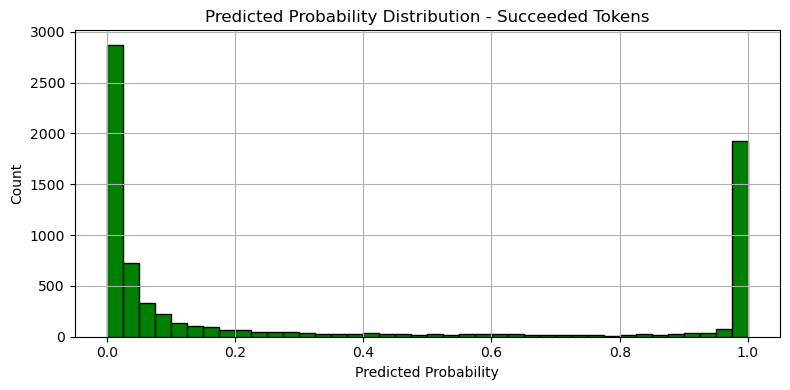
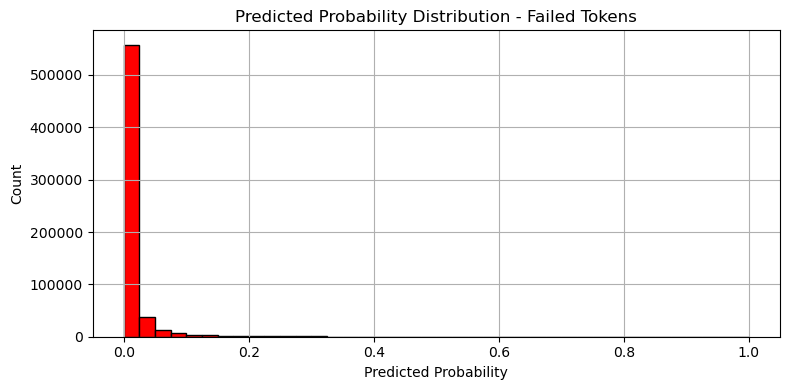
실패 logloss: 0.001683
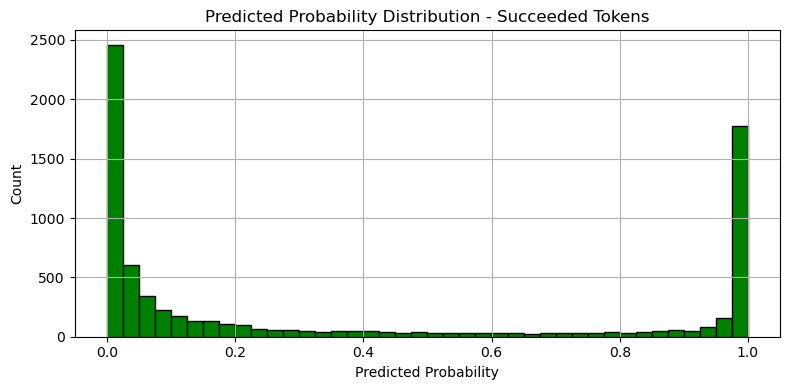
성공 logloss: 0.610846
😱 문제점
train set에 없는 wallet이 test set에 등장하는 경우가 많아 test logloss는 더 안 좋아짐
test 에 있는 코인 478832개 중 56988개에서 wallet_success_rate 가 결측치
test prediction 기반 wallet success rate 보강한다면?
train 기반 wallet_success_rate 계산(기존 방식)
test 에서 predicted_probability ≥ threshold(e.g 0.95)인 코인에서 참여한 wallet을 success로 간주
이 wallet들을 포함해 전체 wallet_success_rate를 재계산
그걸 다시 test에 집계 특성(mean, std, min, max, sum)으로 넣기
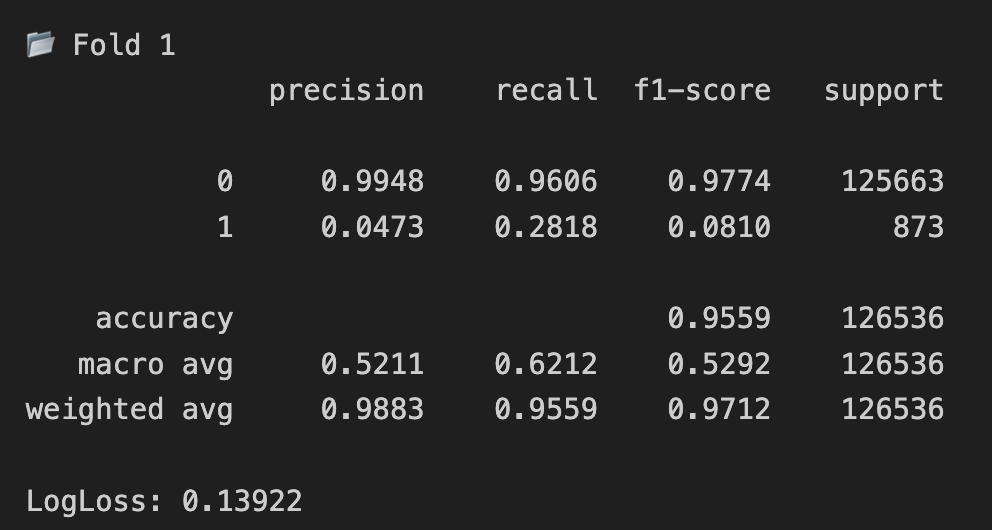
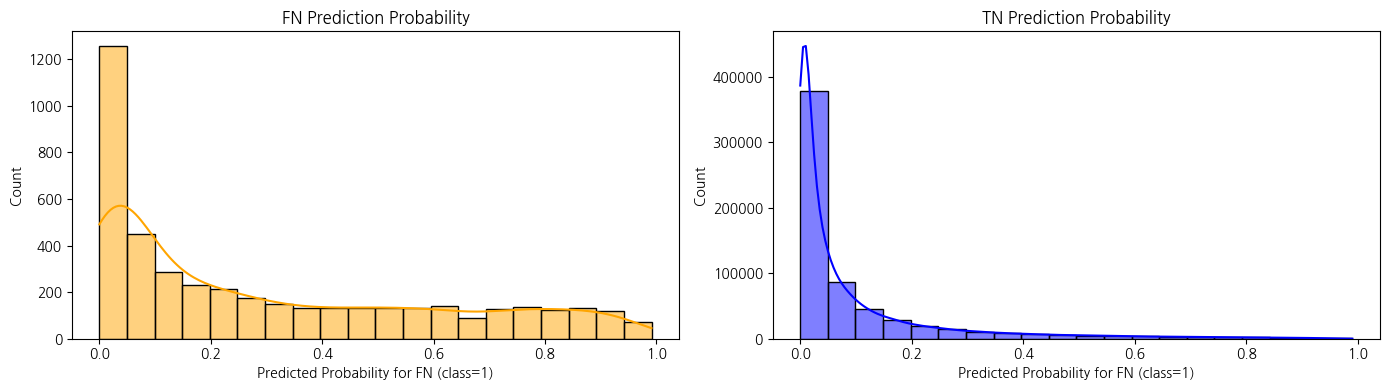
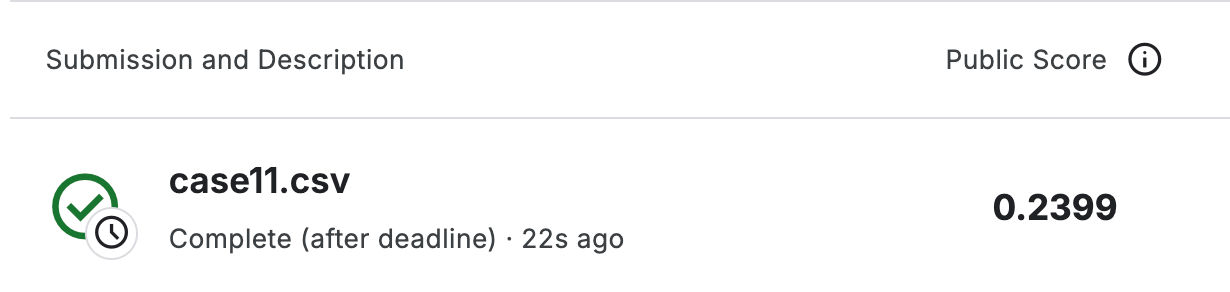
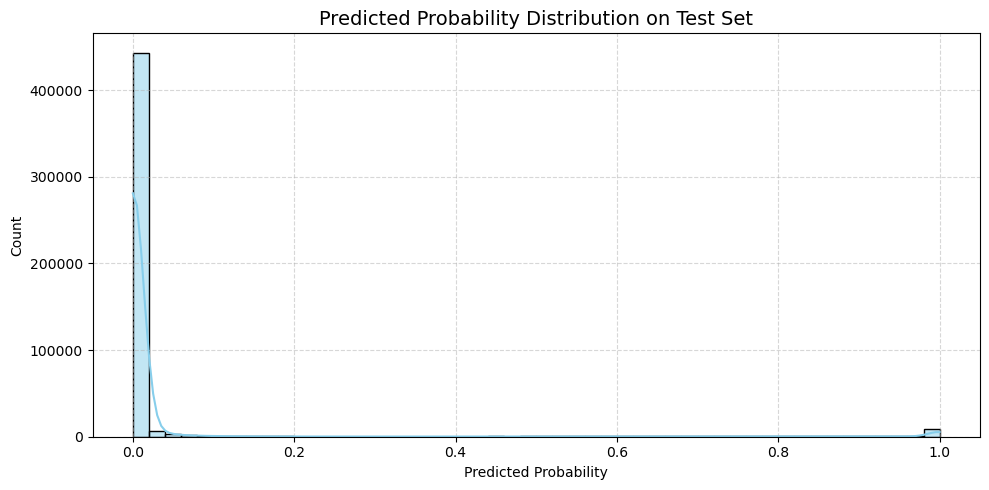
test prediction 기반 wallet success rate 보강하기 전 test logloss: 0.2399
보강 후 test logloss: 0.1684
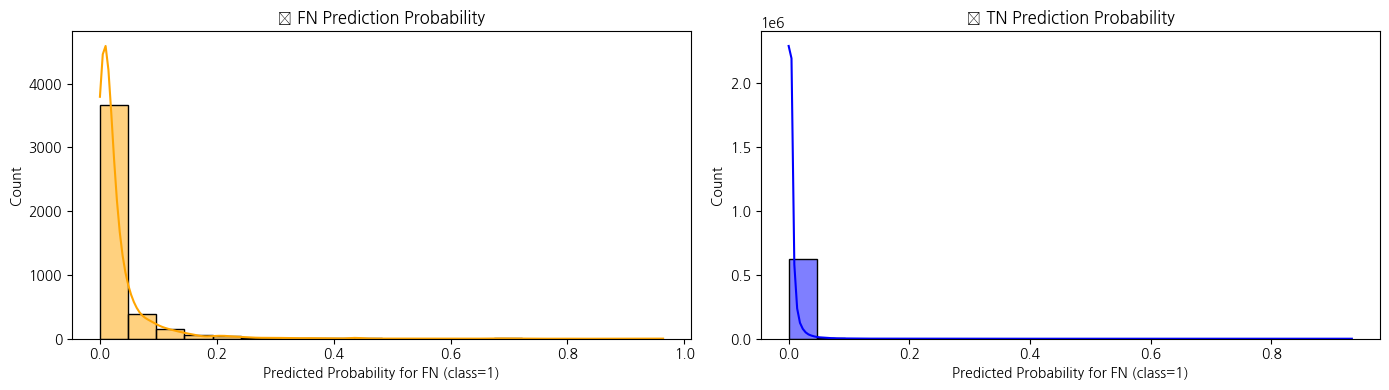
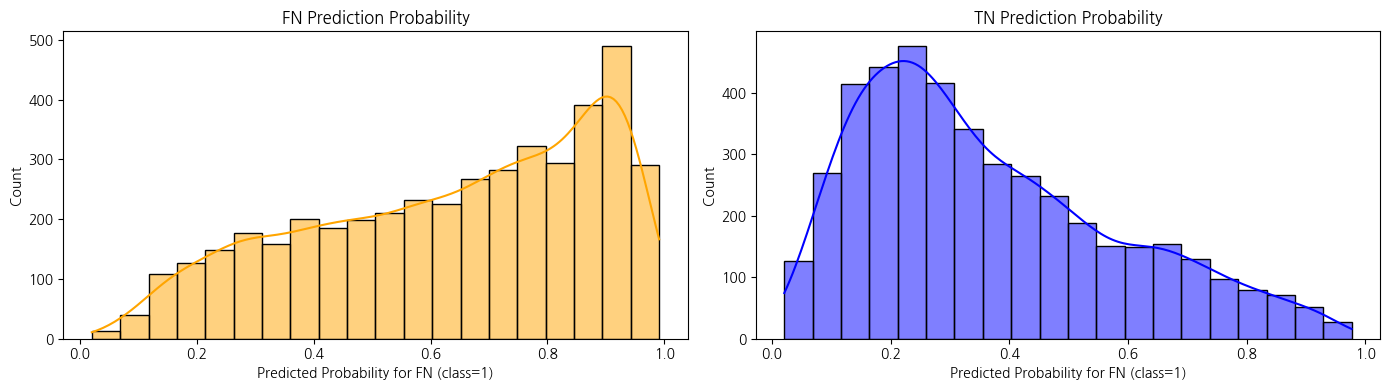
→ 보강 후로 0근처로 확률이 늘어나면서 negative 예측이 확신을 가지게 된 것으로 보임
→ FP(실패인데 성공으로 예측)이 줄어들은 것 같음.
wallet 정보를 보강하기 위한 API 들을 알아봄 → 내용 정리하기
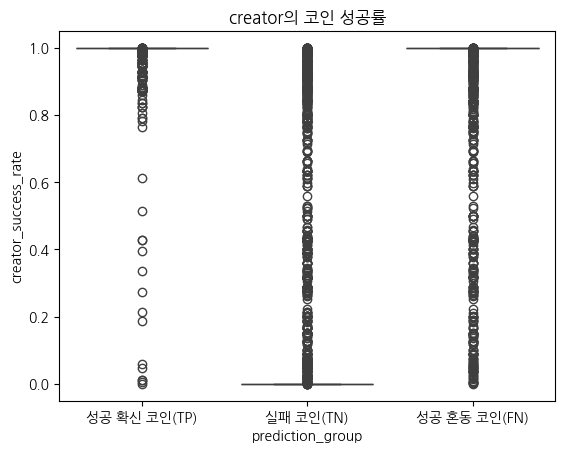
creator_success_rate
토큰 발행자가 발행한 코인 중 성공한 코인의 비율
실패 logloss: 0.001566
성공 logloss: 0.473295
wallet_success_rate 과 마찬가지로 testset 에는 학습 시킬 때는 몰랐던, test 데이터에서 처음 등장하는 토큰 발행자가 있다는 문제점이 있다.. 처음 등장하는 지갑(거래자)보다 처음 등장하는 토큰 발행자가 더 많다 🥲
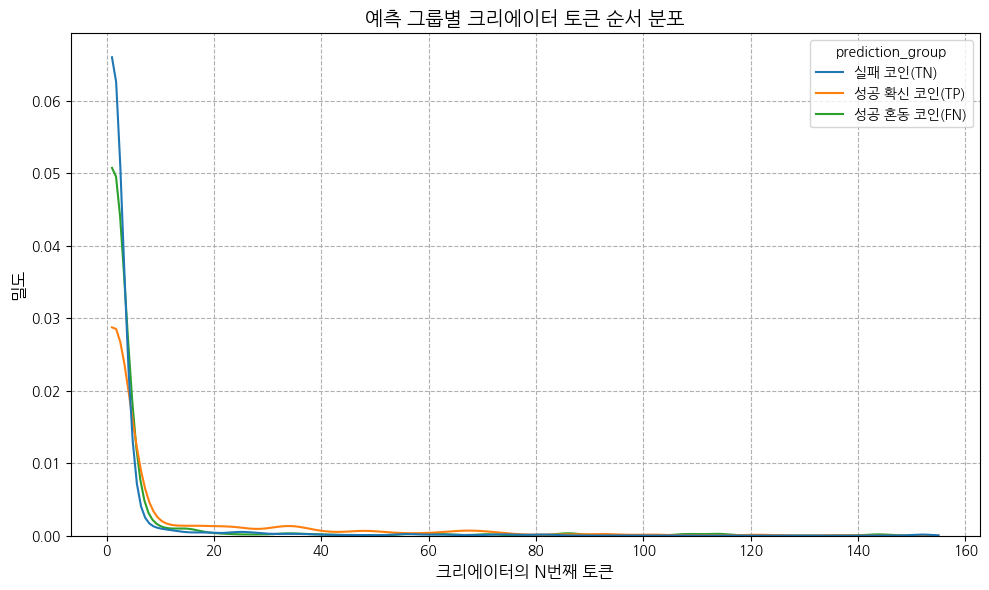
creator 가 몇 번째로 발행한 코인인지?
코인 발행자들은 대부분 1-2개 정도 발행했다. (대부분의 토큰이 각 크리에이터의 첫 번째 토큰임)
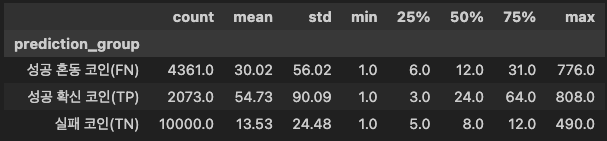
평균적인 순서는 TP > FN > TN
표준편차도 TP가 가장 높음 → TP 그룹은 경험이 적은 크리에이터부터 많은 크리에이터까지 다양하게 분포
최댓값을 봤을 때는, 실패 코인이라도 토큰을 많이 발행한 사람은 존재하지만 평균은 낮은 편
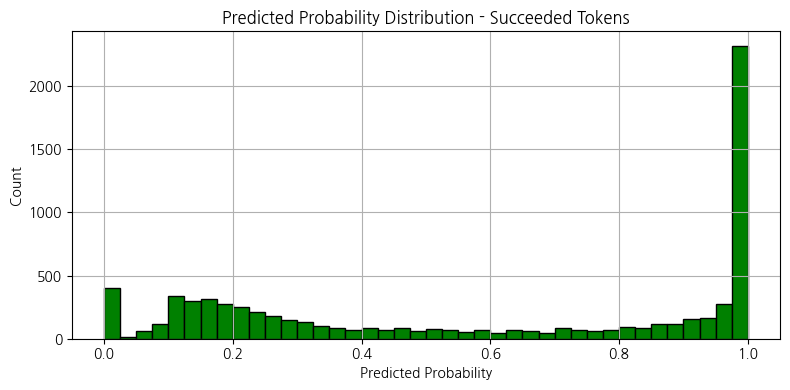
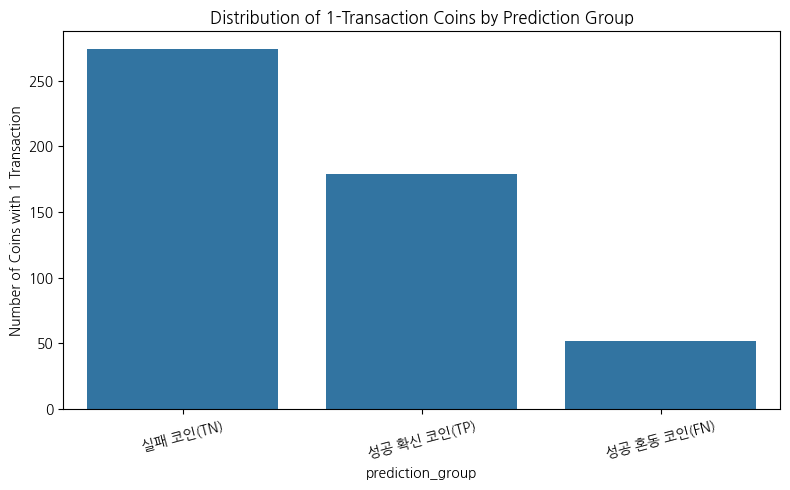
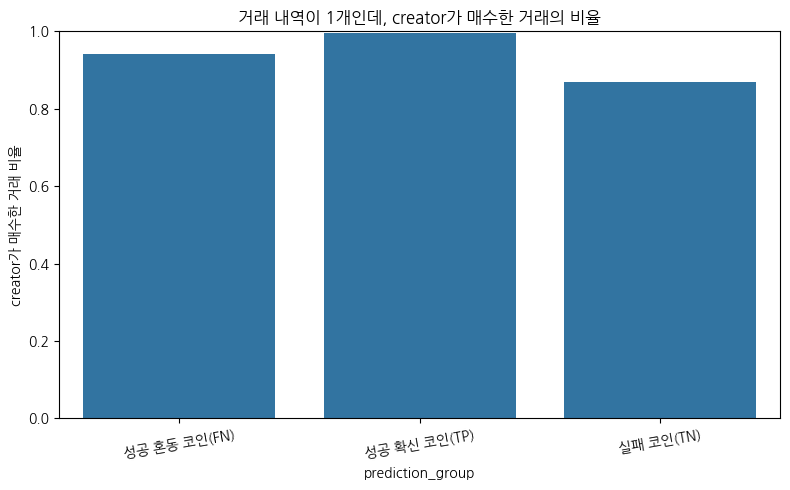
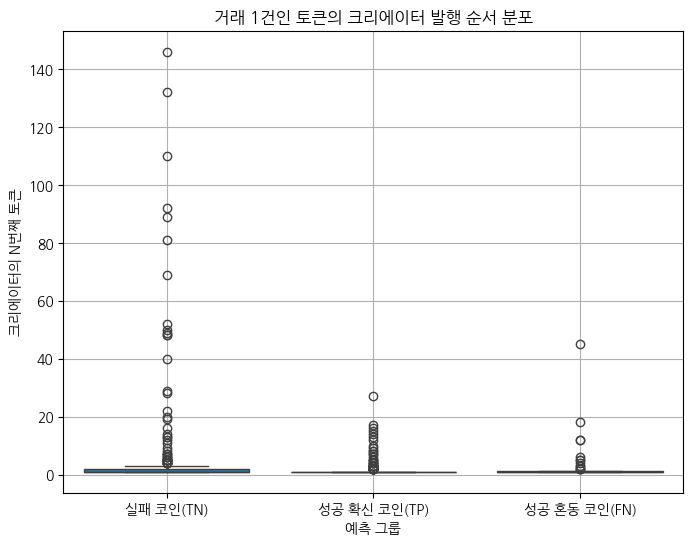
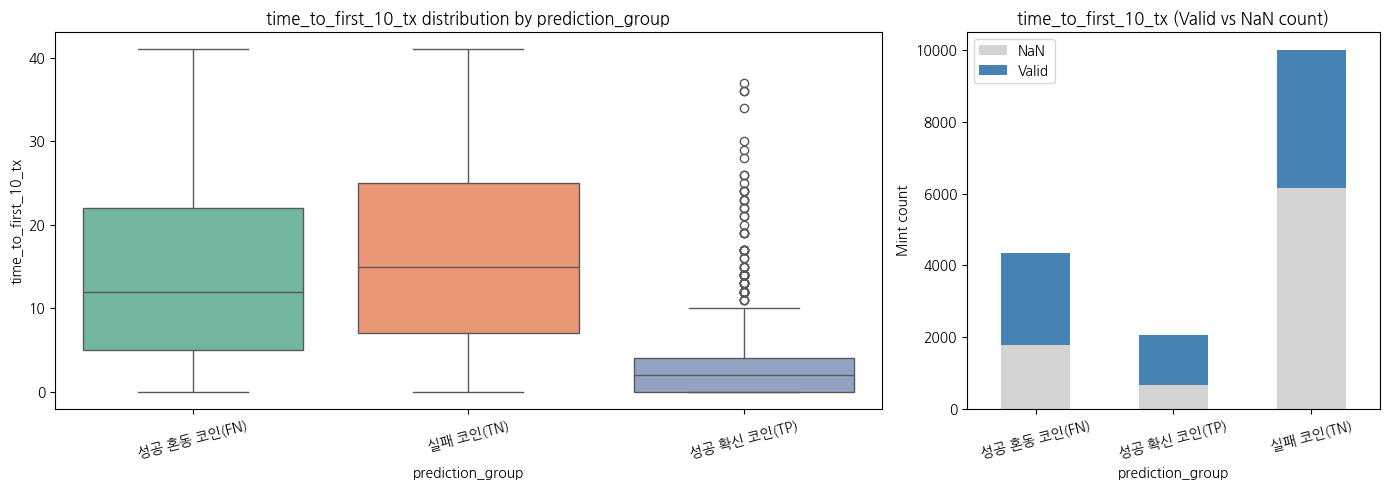
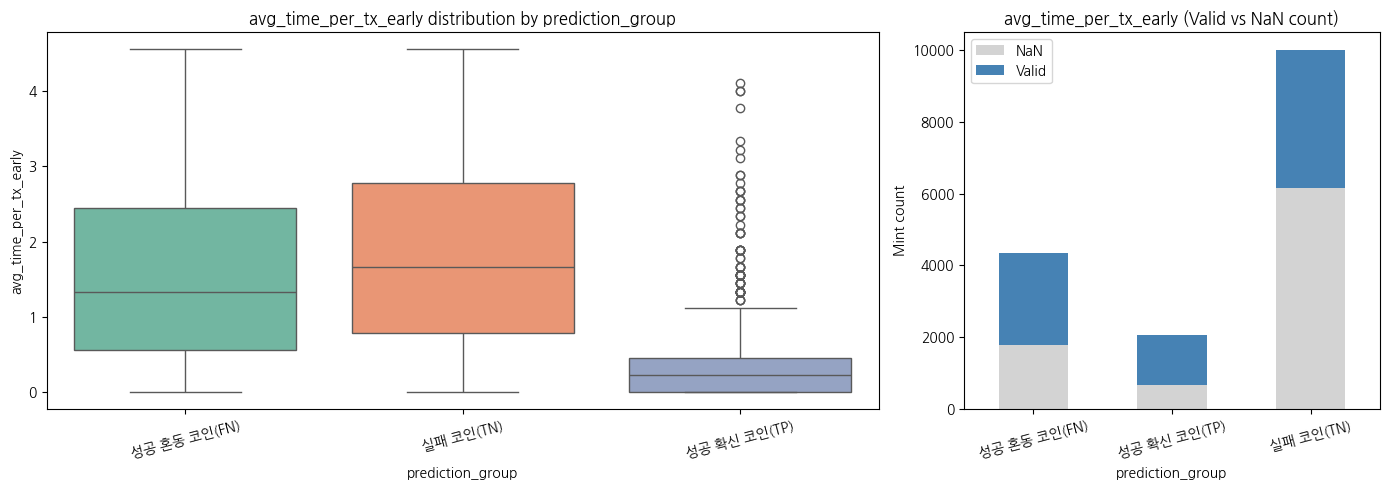
거래가 1건이면서 성공한 코인들은 경력자인 크리에이터가 발행한 코인일까?
거래가 1건밖에 없는 코인이라 정보가 적지만,
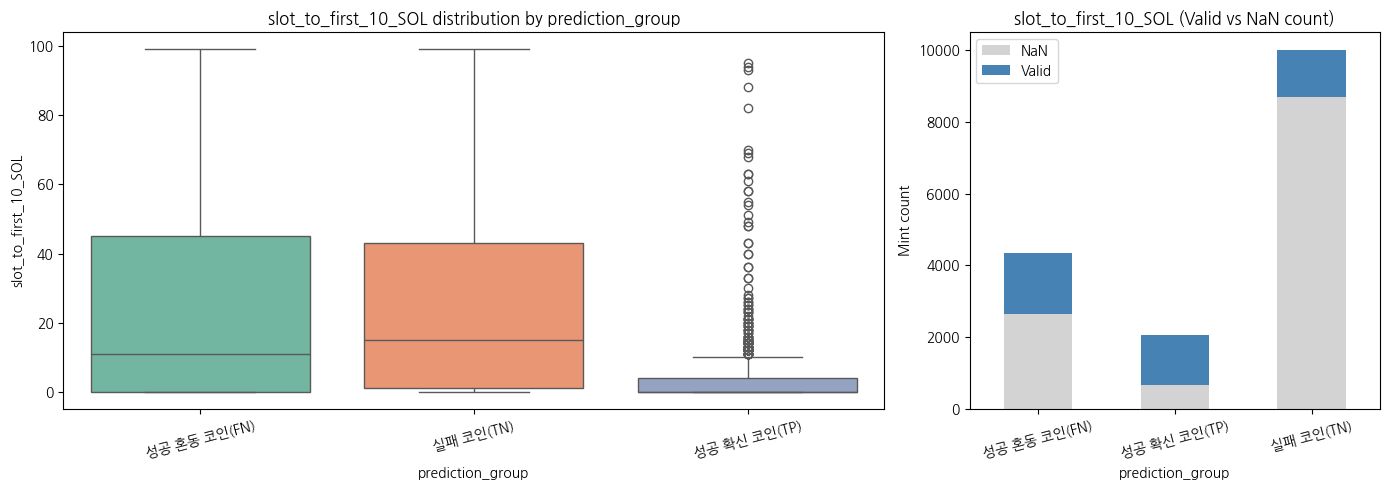
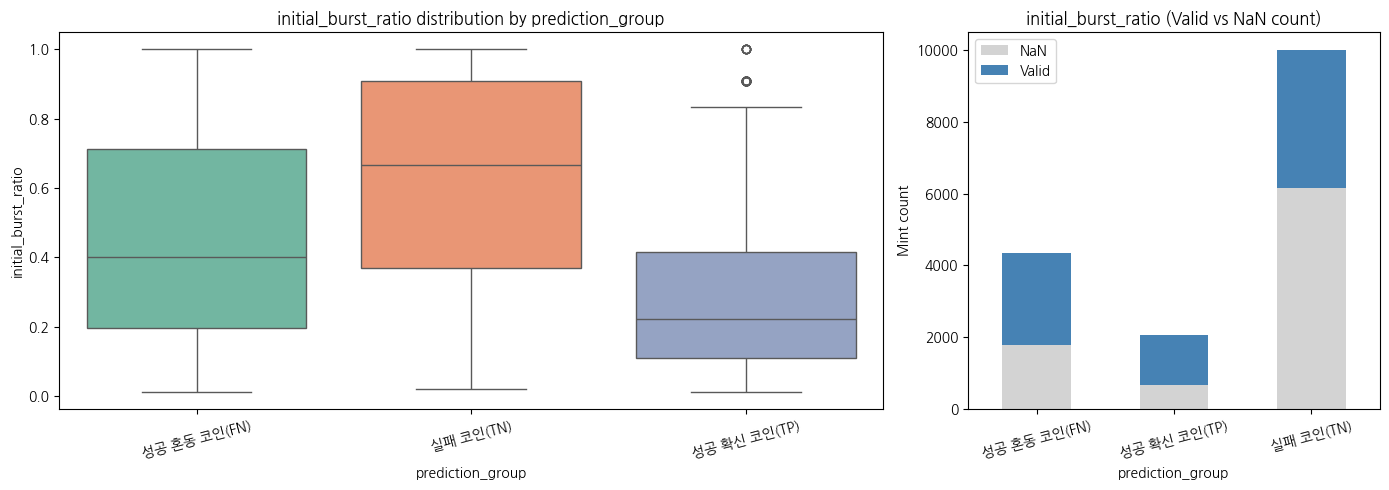
성공 확신 코인일수록 초기에 성공한 케이스가 많음
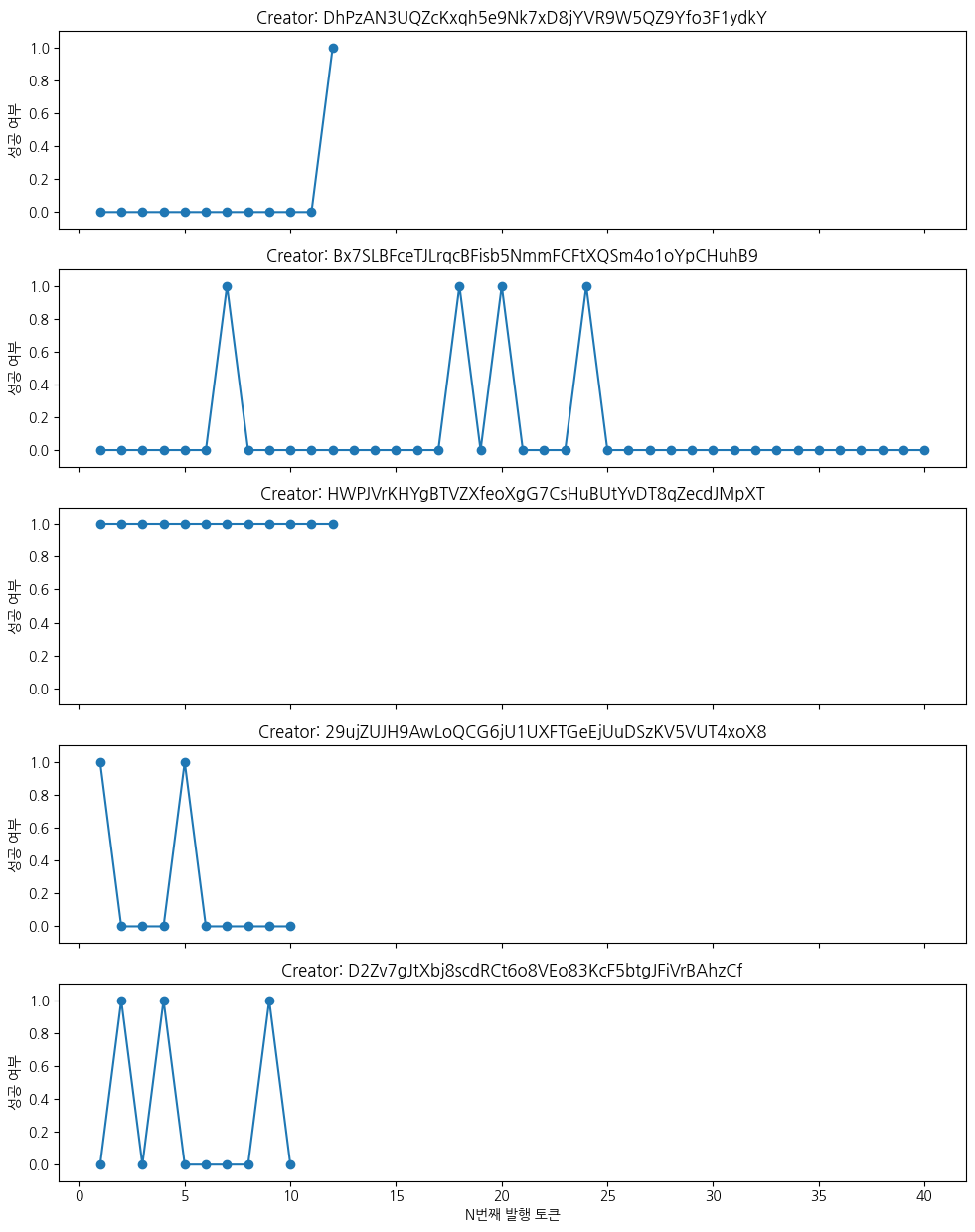
일관된 성공 전략을 가진 크리에이터는 일부 존재하지만, 대부분은 한두 번 성공한 후 다시 실패하거나, 초기 실패 후 성공한 뒤 다시 실패하는 등, 성공/실패가 반복되는 양상