| 실험 개요 | • adam , adamw, sgd optimizer 별로 30회씩 실험 진행• 각 실험에서 학습률(learning rate)만 변경하여 테스트 • 평가 방식으로는 5-fold 학습 후 각 fold의 최소 validation loss를 기록해 • fold별 최소 validation loss의 평균 + 표준편차 로 하이퍼파라미터들을 평가 → fold 간 성능 안정성을 고려하기 위해 표준편차를 포함해 평가함 |
| adam | • 탐색 learning rate 범위: 2e-4 ~ 6e-4 |
| adamw | • 탐색 learning rate 범위: 1e-5 ~ 5e-4 |
| sgd | • 탐색 learning rate 범위: 1e-3 ~ 5e-2 |
| 결론 | • wce loss 케이스보다 성능을 확실히 개선한 optimizer, lr 조합은 없음 • 그나마, validation set에서 text 성능이 올라간 adamw가 적합할 것으로 보임 |
| optuna로 더 성능이 좋은 하이퍼파라미터 튜닝을 찾지 못한 이유 | 데이터가 작고 일부 클래스 표본이 적어 fold마다 성능 분산이 크게 나타났고, 이로 인한 평가지표가 안정적이지 않아서 optuna의 탐색 방향이 쉽게 흔들렸을 것으로 생각됨 |
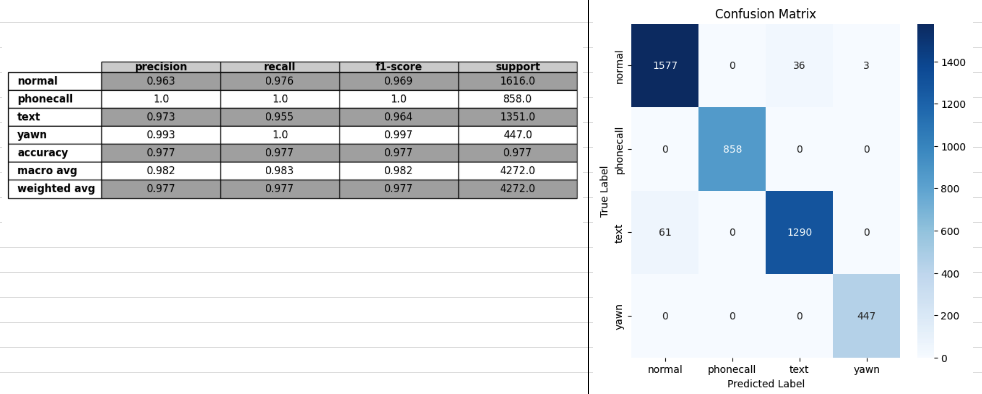
- loss wce(최종으로 가장 성능 좋은 케이스)
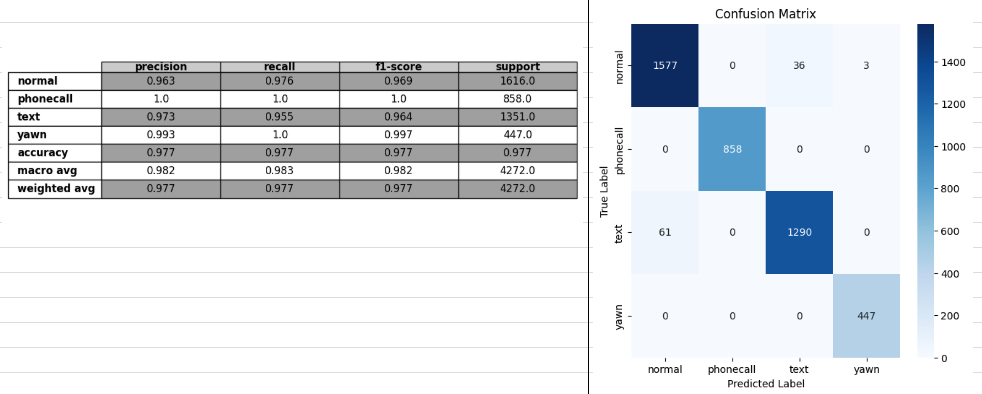
train
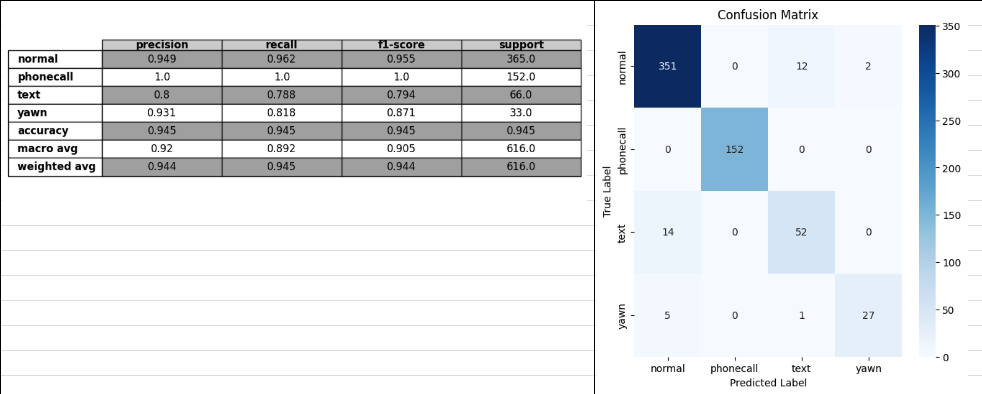
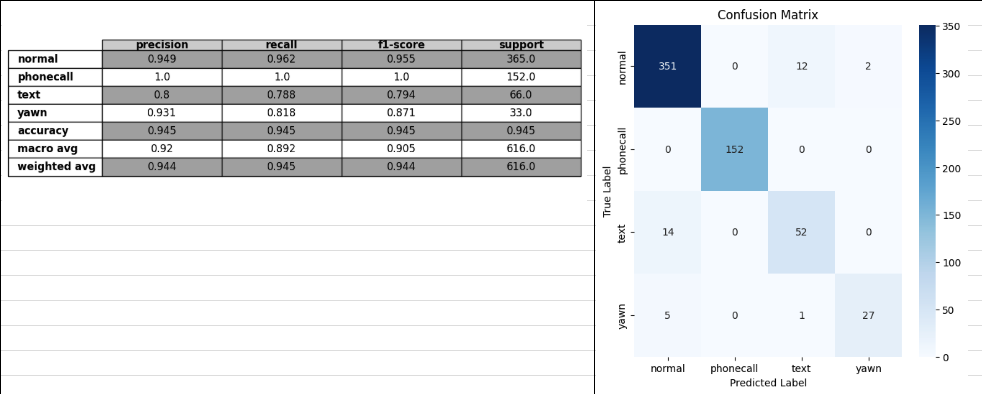
val
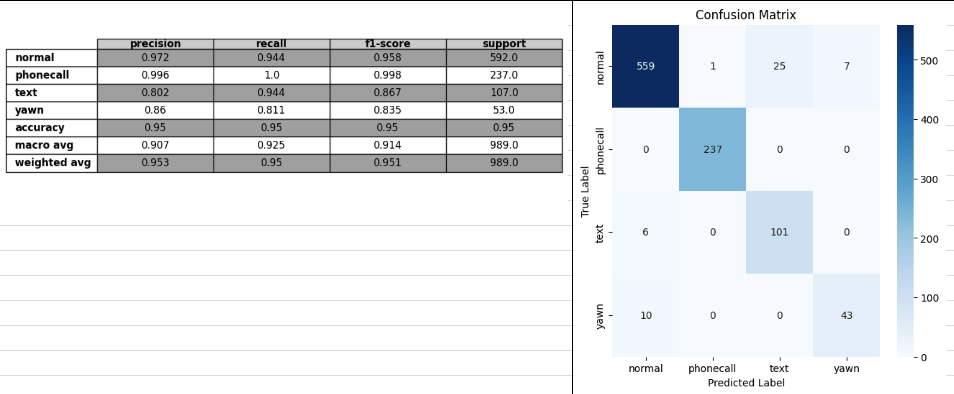
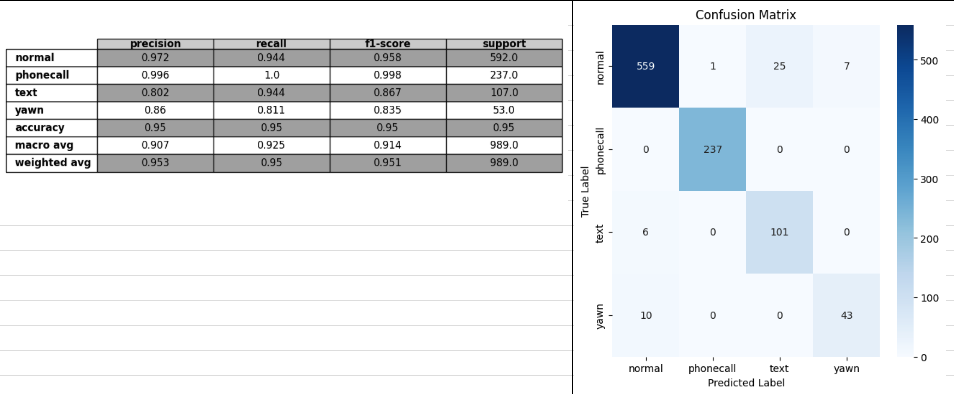
test
- optuna adam
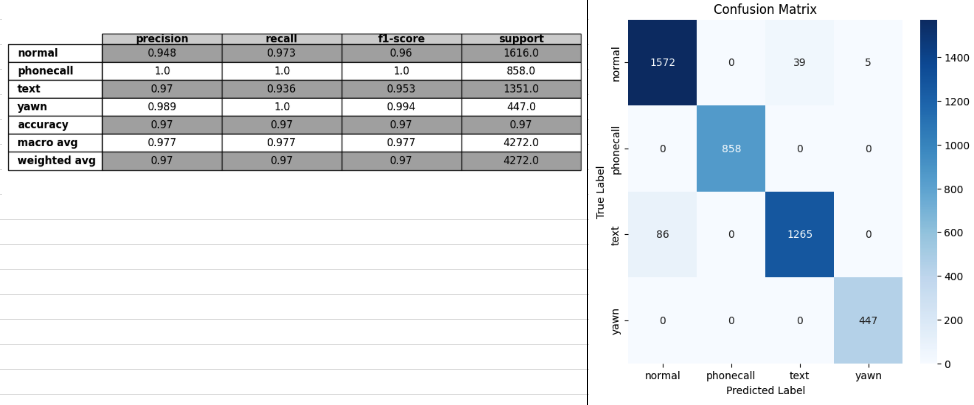
train
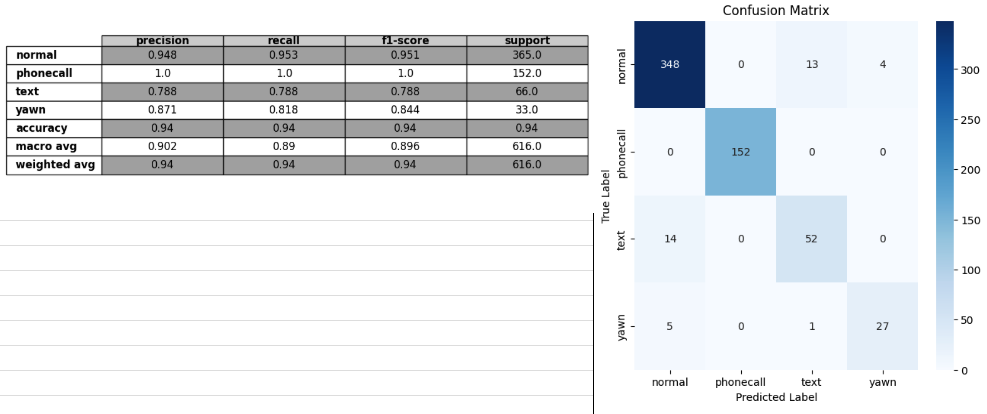
val
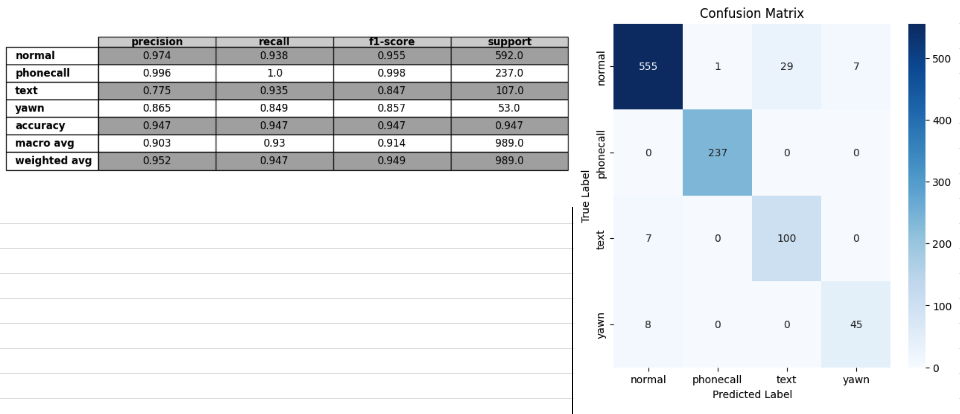
test
- loss wce(최종으로 가장 성능 좋은 케이스)
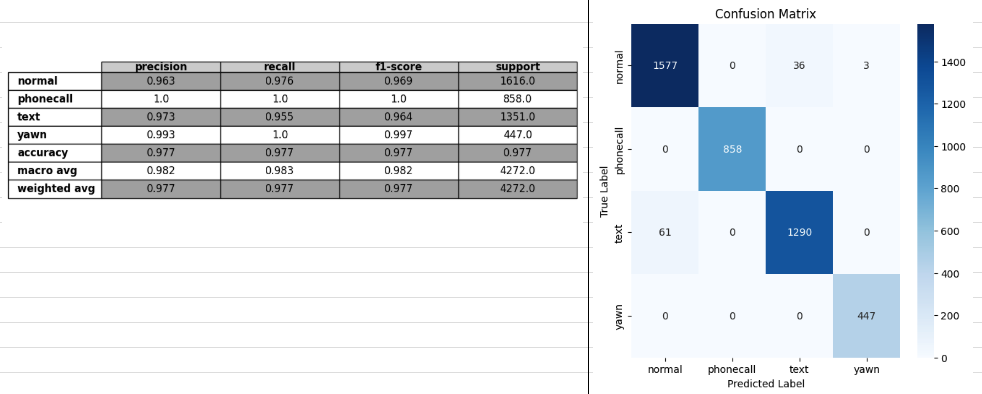
train
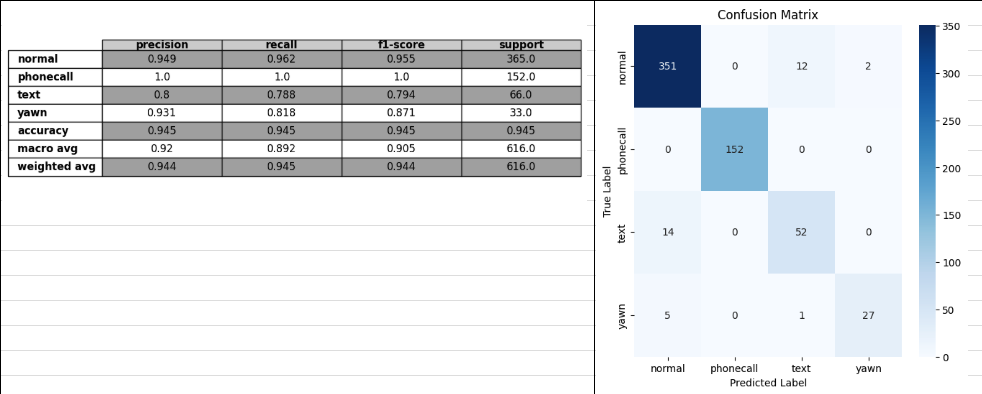
val
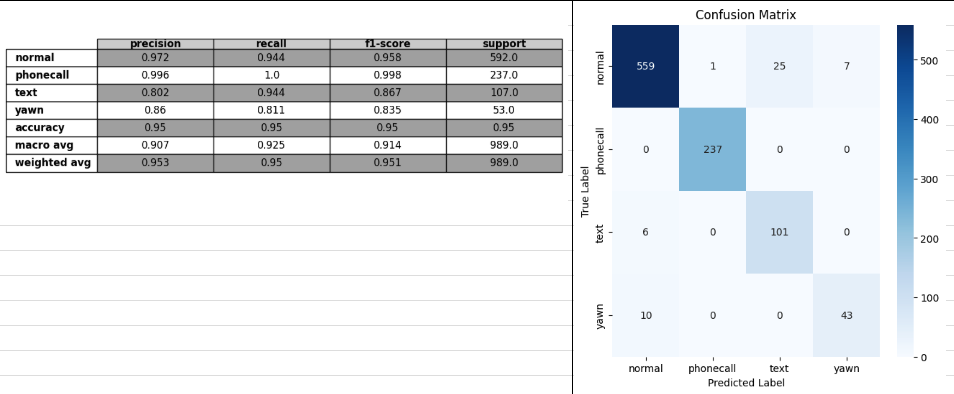
test
- optuna sgd
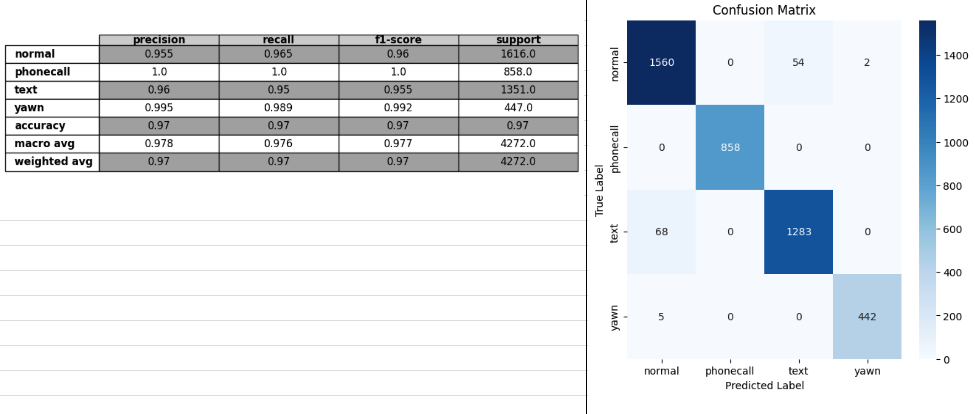
train
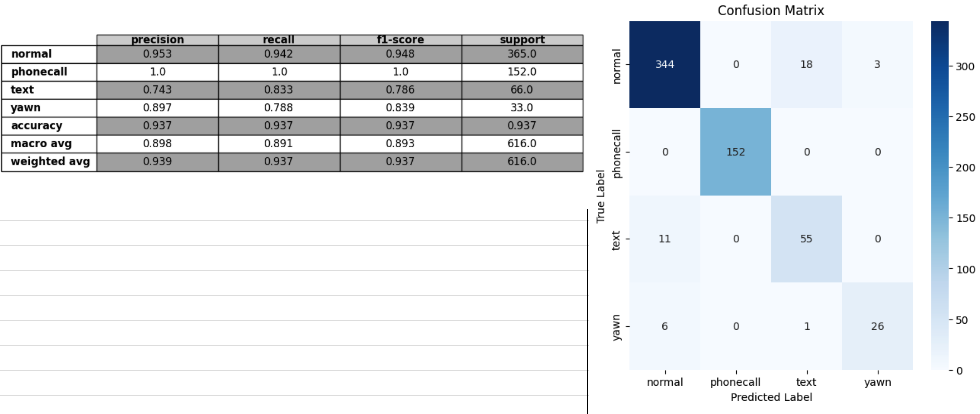
val
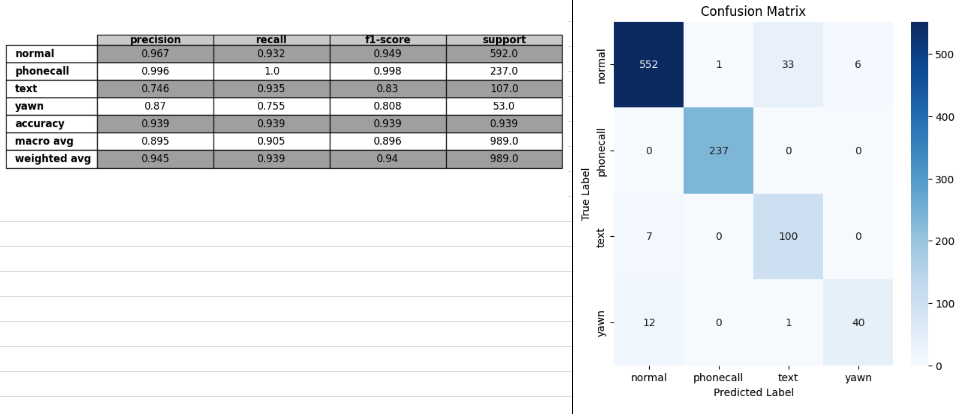
test
- loss wce(최종으로 가장 성능 좋은 케이스)
train
val
test
- optuna adamw
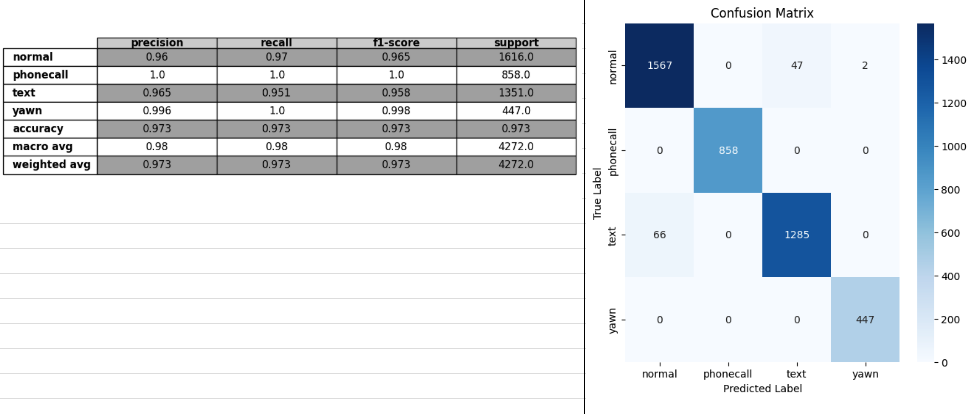
train
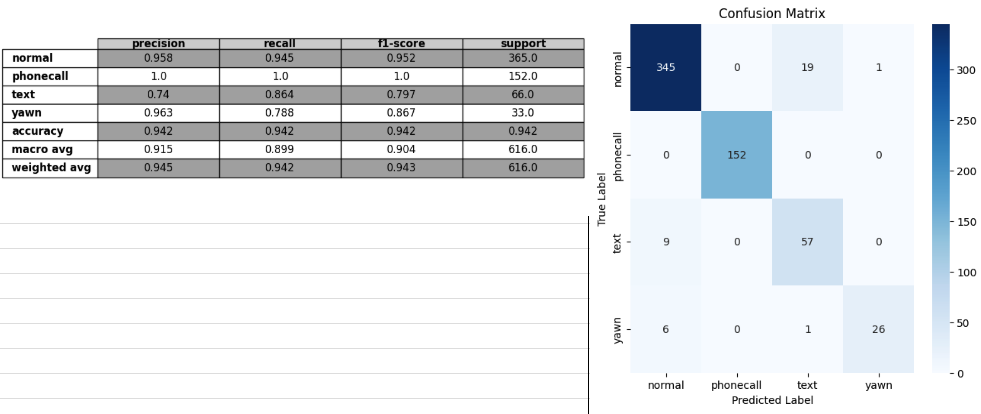
val
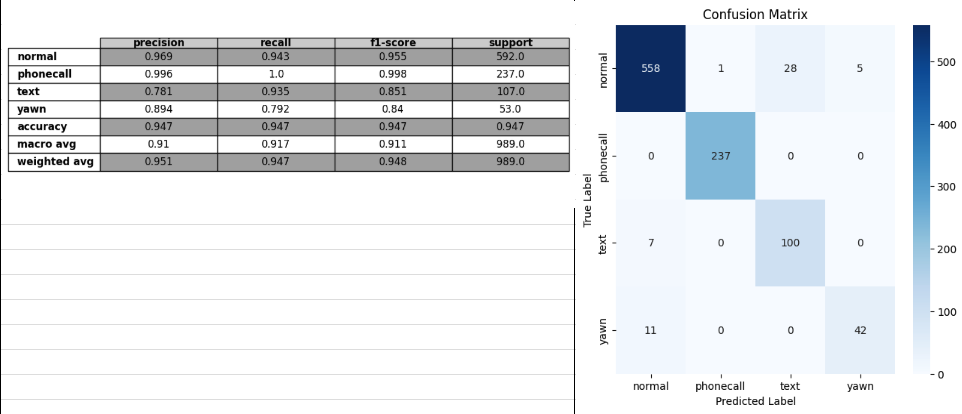
test